Background¶
An autoencoder (AE) is a subclass of variational inference that takes an input dataset (can be anything! - images, text, video, voice recordings etc.), compresses this datset to a low dimensional representation, then reconstructs the image from this low-dimensional representation. Here is a schematic from the original paper.
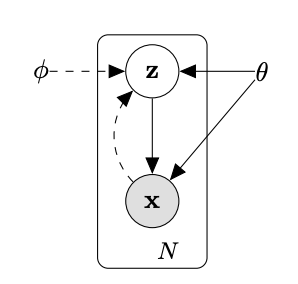
Importantly, this has two parts -
- The Encoder:
This is what reduces the dimensionality of the input dataset (from X to Z). It is crucial for the data compression aspect of the alogrithm.
- The Decoder:
This tries to reconstruct the input image from the low dimensional representation Z. It is crucial for the generative aspect of the algorithm.
The encoder and decoder are both neural networks that learn to ‘efficently’ autoencode the input data X. ‘Efficiently’ depends on the loss function.
- A vanilla autoencoder simply minimzes the mean squared error (MSE) between the input data and the generated data. While this still compresses the data to a low dimensional representation, it performs poorly as a generative model since we do not know what form the distributions take in the latent space. Are they normally distributed? If so, what is their mean and variance? Since we do not know the distribution, we cannot sample from it and thus, cannot generate new images after the model has been trained.
- A variational autoencoder (VAE) solves this problem. This imposes a regularization term in the loss function that penalizes deviation away from a normally distributed prior with mean 0 and variance 1. Thus, all the learned distributions in the latent space will be close to this prior, allowing us to sample from it.
To understand how this works, we can test it on the MNIST dataset (dataset containing 28*28 pixel images of handwritten digits from 0-9). Once a VAE is trained, we can sample from the latent space to generate new images. The image below shows an example of newly generated data on the left and the latent space learned by the model labeled by the digit. This image was taken from here.
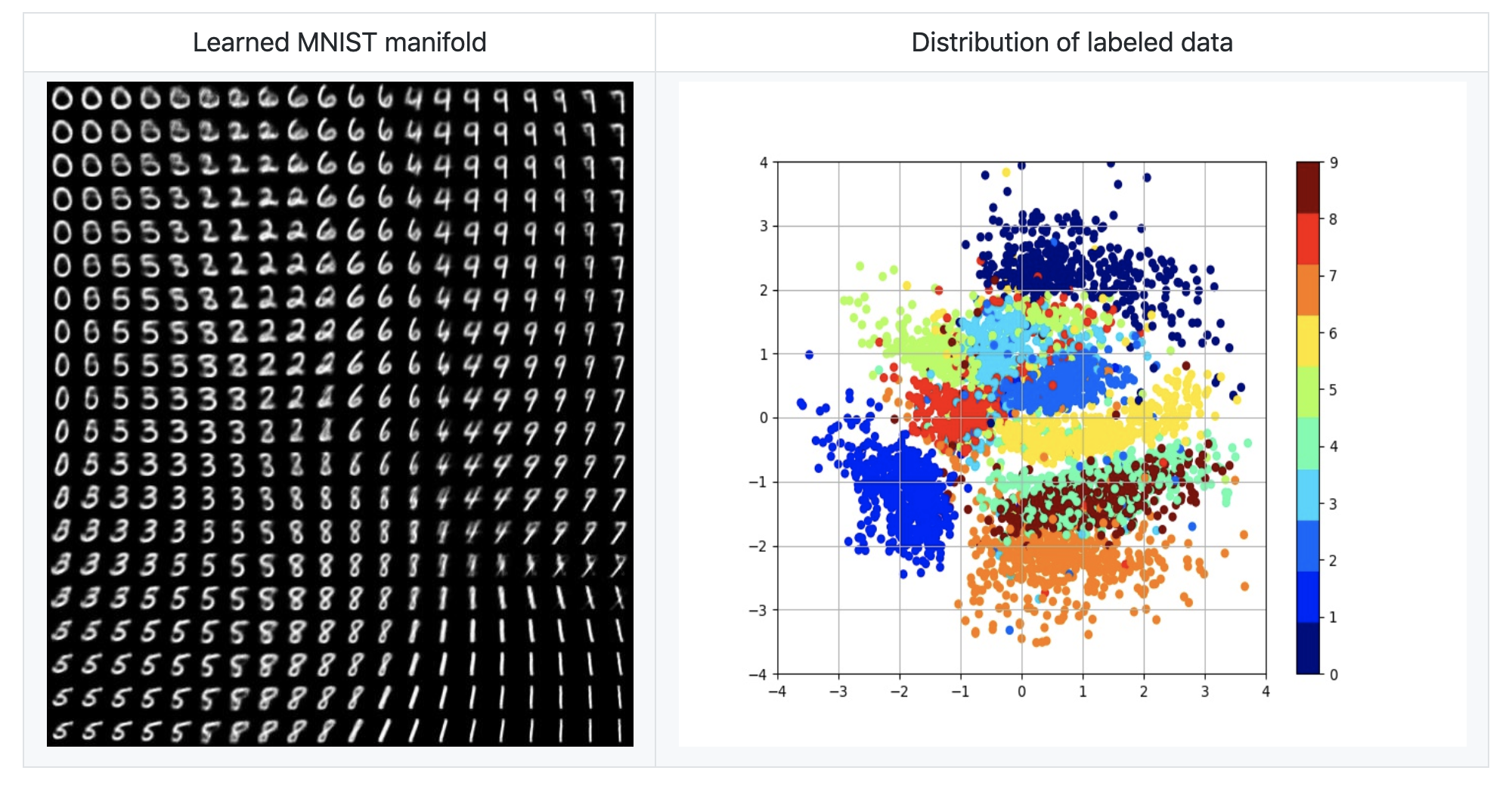
The VAE has learnt clusters for every digit label with just 2 latent dimensions! And sampling from these dimensions will generate a random digit depending on where you sample from.
- A conditional variational autoencoder (CVAE) adds a condition or combination of conditions during training. This is useful because, as an example from the MNIST dataset, What if we only wanted to generate an image of a 5? This is not so easy because each digit label forms its own cluster that is nearly independent of the others.
In a CVAE, we can specify during training that the images that it sees are of a certain label (for example, that it is a 5) and so it will only autoencode information that is not related to the digit label. After training, if we were to sample from the latent space and ask for a digit label 5, this is what we would get
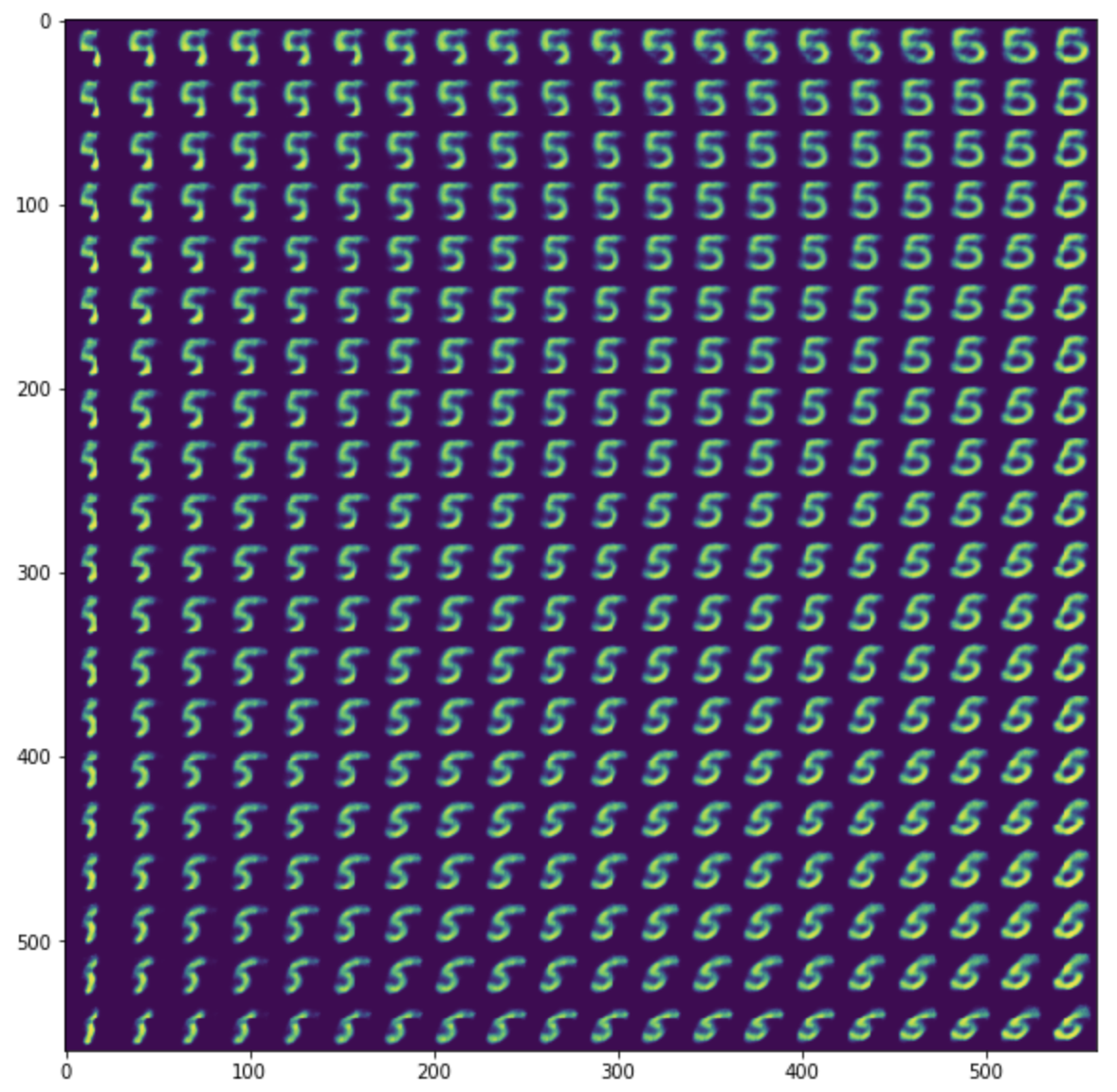
The CVAE now encodes information like texture, angle of 5’s in the latent space and not the digit label.